

In the rapidly shifting landscape of artificial intelligence, a critical transition is underway: the move from cloud-dependent chatbots to sovereign, on-device agents. Leading this charge is Gemma 4, the latest evolution from Google DeepMind. Released under the permissive Apache 2.0 license, Gemma 4 is not merely an incremental update to its predecessor; it is a fundamental architectural redesign aimed at democratizing access to state-of-the-art reasoning, multimodality, and agentic workflows directly on local hardware—from high-end workstations to the smartphone in your pocket .
The Leap Forward: Architectural Superiority
While previous open-weight models focused primarily on linguistic fluency, Gemma 4 is engineered specifically for efficiency and agency. It introduces a family of four variants—E2B, E4B, 26B A4B (MoE), and 31B Dense—allowing developers to trade off between speed, memory footprint, and raw intelligence without sacrificing data privacy .
1. Rethinking Efficiency: The “Effective” Parameter Count
The most groundbreaking shift lies in the E2B and E4B models. Unlike standard dense models, these utilize Per-Layer Embeddings (PLE) . This technique gives each decoder layer its own small embedding for every token. Consequently, while the total parameter count sits at roughly 5B and 8B respectively, the “effective” parameters used for active computation are only 2.3B and 4.5B . For the edge, this translates to extreme efficiency. According to Google AI Edge, the E2B variant can run in under 1.5GB of memory using quantization, enabling near-zero latency on devices ranging from the Raspberry Pi 5 to the latest Android flagships .
2. The “Thinking” Revolution and Agentic Workflows
Gemma 4 introduces a native “Thinking Mode” , controlled via the <|think|> token . This allows the model to pause, perform Chain-of-Thought (CoT) reasoning internally, and plan multi-step actions before outputting a final response. For developers building autonomous agents, this is transformative. The model supports native Function Calling through specific control tokens (<|tool_call|>), enabling it to interact with external APIs, databases, or IoT devices without the hallucinations that plague smaller models .
3. Massive Context and Native Multimodality
Gemma 4 shatters memory constraints with context windows of up to 256K tokens (on the 26B and 31B models), allowing it to ingest entire codebases or lengthy legal documents in a single pass . Furthermore, it is natively multimodal. While all variants handle text and images, the E2B and E4B models also natively process audio and video, making them ideal for real-time transcription and on-the-fly visual Q&A without an internet connection .
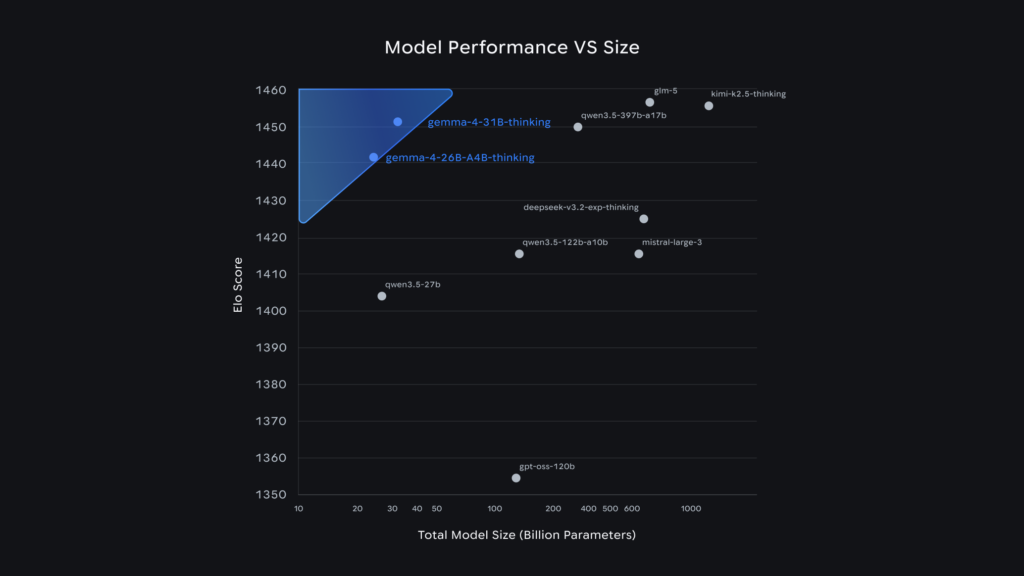
Benchmarking the Leap: Measured Intelligence
The raw data confirms the leap in capability. On the AIME 2026 (mathematical reasoning) benchmark without tools, the 31B model scores 89.2% , a staggering increase from the previous generation’s 20.8%. Similarly, on LiveCodeBench v6, Gemma 4 31B achieves 80.0% compared to Gemma 3’s 29.1%, and it ranks #3 on the Arena AI leaderboard for open models .
Empowering the Specialists: Who Benefits Most?
Gemma 4’s diverse architecture provides specific, quantifiable advantages to distinct professional categories.
For Enterprise Architects and Privacy-First Industries
The shift to Apache 2.0 is a seismic event for enterprise legal teams. Unlike the restrictive Gemma Terms of Service used previously, Apache 2.0 explicitly grants rights for commercial use, modification, and redistribution . For healthcare, finance, and defense sectors operating under strict data sovereignty laws, Gemma 4 offers “frontier intelligence” that runs entirely on-premise or air-gapped, eliminating the risk of data leakage inherent in cloud API calls .
For Mobile and Edge Developers (E2B/E4B)
For mobile engineers, Gemma 4 is a hardware-accelerated gift. Google has confirmed that these models are the foundation for Gemini Nano 4 and are optimized to run on specialized AI accelerators from Qualcomm and MediaTek . Developers can use the AICore Developer Preview to perform OCR (Optical Character Recognition), handwriting recognition, and real-time audio transcription directly on the device, using up to 60% less battery than previous versions while running 4x faster .
For Researchers and Complex Reasoners (26B/31B)
Researchers leveraging the 26B Mixture-of-Experts model find a “sweet spot” of performance. Although it has 26B total parameters, it only activates 3.8B during inference. This means it runs with the speed of a small model but delivers the deep knowledge base of a large one . This is ideal for agentic workflows requiring long-running task planning without prohibitive compute costs.
Best Practices for Mastering Gemma 4
To extract maximum value, developers must move beyond simple prompting and embrace the model’s structural features:
- Master the Control Tokens: Gemma 4 relies on specific syntax. Always delineate turns with
<|turn|>and system prompts withsystem. When using function calling, ensure strings are enclosed with the special<|"|>delimiter to prevent parsing errors . - Utilize System Prompts for Persona: Use the native
systemrole to define the model’s constraints rigidly. This is far more effective than “role-playing” in the user prompt. - Optimize Hardware Mapping:
- Manage “Thought” Context: In multi-turn conversations, you must strip the model’s internal “thinking” tokens (
<|channel|>) before passing the history back to the model, unless you are in the middle of a function-calling loop. For long-running agents, summarizing prior “thoughts” prevents reasoning loops .
Getting Started: From Zero to Inference
Getting Gemma 4 running locally is remarkably streamlined. The ecosystem supports Hugging Face transformers, Ollama, llama.cpp, and LiteRT-LM.
Quick Start with Ollama
For developers using macOS or Linux, Ollama v0.20.0+ offers the fastest route:
Bash: ollama run gemma4This pulls the default 4B model (~9.6GB). For the powerful MoE variant: ollama run gemma4:26b
Download Ollama from https://ollama.com/download
Python with Transformers
For researchers needing granular control, the Hugging Face transformers library provides native integration:
The Sovereign AI Stack
The launch of Gemma 4 represents a philosophical shift toward digital sovereignty. By combining the legal freedom of the Apache 2.0 license with the technical prowess of “Thinking Mode” and native multimodality, Google has handed developers the keys to the kingdom. Whether you are building an autonomous supply chain agent running on a Raspberry Pi or a privacy-secure medical transcription tool on a smartphone, Gemma 4 stands as the definitive new standard for open, on-device AI .
Who will be benefited the most ??
1. Enterprise Architects & Privacy-First Industries
- Who they are: Healthcare providers, financial institutions, defense contractors, legal firms.
- Why they benefit: The Apache 2.0 license allows commercial use without legal restrictions. These organizations can run frontier-level AI entirely on-premise or air-gapped, eliminating the risk of sensitive data leaking through cloud API calls. This is critical for complying with data sovereignty laws like HIPAA, GDPR, or federal security mandates.
2. Mobile & Edge Developers (E2B/E4B users)
- Who they are: Android and iOS app developers, IoT device engineers, embedded systems designers.
- Why they benefit: The E2B variant runs in under 1.5GB of memory and operates 4x faster while using 60% less battery than previous models. They can build real-time OCR, handwriting recognition, audio transcription, and language translation apps that work without an internet connection directly on smartphones, Raspberry Pi devices, or smart home hubs.
3. Software Developers & Engineers
- Who they are: Professional coders, open-source contributors, DevOps engineers.
- Why they benefit: With the 256K token context window, developers can feed entire codebases into the model in a single prompt. The native Function Calling capability allows Gemma 4 to interact with APIs, databases, and development tools. They can perform offline code generation and refactoring while keeping intellectual property strictly local.
4. Researchers & Data Analysts
- Who they are: Academic researchers, data scientists, business intelligence analysts.
- Why they benefit: The 26B Mixture-of-Experts (MoE) model activates only 3.8B parameters during inference, delivering the knowledge of a large model with the speed of a small one. This is ideal for long-form synthesis across hundreds of documents, identifying hidden correlations in large datasets, and running complex reasoning tasks without requiring a supercomputer.
5. Content Creators & Educators
- Who they are: Online course creators, language teachers, instructional designers, ed-tech entrepreneurs.
- Why they benefit: The native multimodal support (text, images, audio, video) combined with 140+ language capabilities enables creators to build localized educational tools. For example, a language-learning app can listen to student pronunciation and provide real-time, logic-based corrections—all running locally on a smartphone to preserve user privacy.
6. Autonomous Agent Builders
- Who they are: AI engineers, robotics developers, automation specialists.
- Why they benefit: The dedicated “Thinking Mode” (Chain-of-Thought reasoning) allows the model to plan multi-step actions before executing. Combined with native tool-calling tokens, developers can create agents that autonomously navigate websites, control IoT devices, or manage supply chains without constant cloud connectivity.
Summary Table
| Beneficiary Category | Primary Gain | Key Model |
|---|---|---|
| Enterprise/Privacy sectors | Data sovereignty, legal compliance | Any (on-premise) |
| Mobile/Edge developers | Battery efficiency, offline operation | E2B, E4B |
| Software engineers | Codebase ingestion, local IP protection | 31B Dense |
| Researchers/Analysts | Long-form synthesis, cost efficiency | 26B MoE |
| Educators/Creators | Multimodal localization, privacy | E4B |
| Agent builders | Autonomous planning, tool use | 26B or 31B |
Gemma 4 is Google’s latest open-weight AI model family, released under the Apache 2.0 license for commercial use. Whether you are comparing Gemma 4 vs Qwen 3.5, Gemma 4 vs DeepSeek V3, or Gemma 4 vs Llama 4, benchmarks show the 31B dense and 26B MoE variants achieving 89.2% on AIME 2026 and 80% on LiveCodeBench v6. Developers can run Gemma 4 locally on everything from a Raspberry Pi (using the E2B variant with just 1.5GB RAM) to high-end GPUs, with support for Ollama, Hugging Face, and llama.cpp. Key features include 256K context window, native multimodal processing (text, image, audio, video), function calling for agentic workflows, and a dedicated thinking mode for chain-of-reasoning. For privacy-first industries, on-premise deployment ensures data sovereignty, while mobile developers benefit from 60% lower battery usage and 4x faster inference via TurboQuant and per-layer embeddings (PLE). Search how to install Gemma 4, Gemma 4 fine-tuning, or Gemma 4 system requirements to get started with this sovereign AI revolution.
more official documentations : https://deepmind.google/models/gemma/gemma-4/
